In the rapidly evolving field of artificial intelligence (AI), the Reflexion framework has emerged as a significant breakthrough for enhancing the decision-making abilities of AI agents. This innovative approach integrates the concept of self-reflection, allowing AI models to critique their own performance and iteratively improve their responses. Below, we explore what the Reflexion framework is and how it can be implemented.
What is the Reflexion Framework?
The Reflexion framework is a method that enables Language Models (LMs), such as GPT (Generative Pretrained Transformer), to utilize feedback loops for self-improvement. The framework is based on the premise that an AI can act as both the creator and the evaluator of its outputs. After performing a task, the AI uses self-generated feedback to refine its initial response, thereby enhancing its learning process.
Core Components of Reflexion
The Reflexion framework consists of three primary components:
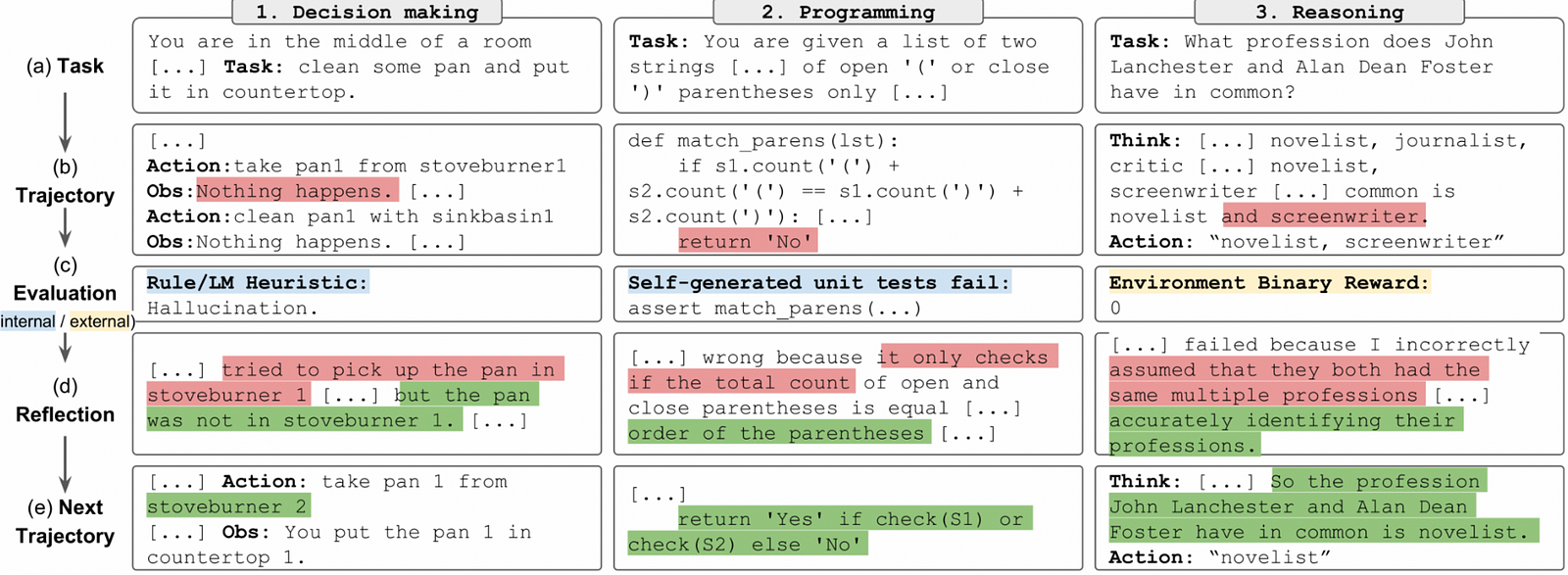
- Actor Model: This is the initial output generator. It performs tasks based on input data and produces an initial response.
- Evaluator Model: This component evaluates the Actor Model’s output. It may include unit tests for code or quality checks for text.
- Self-Reflection Model: After evaluation, this model uses the feedback to provide a critique of the output, which is used to refine the response in the next iteration.
How to Implement the Reflexion Framework
Implementing Reflexion involves several steps to create a loop where the AI learns from its own feedback:
Step 1: Setup the Actor Model
The Actor Model needs to be adept at generating a variety of outputs, depending on the task. For instance, it could be a text generation model like GPT-3 for creative writing or a custom model for generating code.
Step 2: Evaluate the Output
Develop an Evaluator Model capable of assessing the quality of the Actor Model’s output. This might involve comparing text to a style guide or running generated code against predefined tests.
Step 3: Generate Reflection
The Self-Reflection Model critiques the Actor Model’s output. This could be as simple as text feedback highlighting areas for improvement or as complex as a set of revised unit tests for code.
Step 4: Refine and Iterate
With the critique in hand, the Actor Model attempts to revise its output, taking the feedback into account. This process is repeated, with the AI’s performance improving with each cycle.
Step 5: Monitor and Adjust
Implement monitoring tools to ensure the system is learning effectively. Be prepared to adjust the parameters of the Reflexion models or the feedback loop itself.
Pseudo Code
# Pseudocode for implementing Reflexion with LLMs
# Initialize the LLM (e.g., ChatGPT or another model)
initialize_llm(api_key)
# Define the task for the LLM
task_description = define_task()
# Define the Actor model which performs the task
def actor_model(task):
# Generate initial output for the task
output = llm_generate_output(task)
return output
# Define the Evaluator model which critiques the output
def evaluator_model(output):
# Evaluate the output’s quality, efficiency, or correctness
evaluation = evaluate_output(output)
return evaluation
# Define the Self-Reflection model which generates feedback based on the evaluation
def self_reflection_model(evaluation):
# Reflect on the evaluation and suggest improvements
feedback = llm_generate_feedback(evaluation)
return feedback
# Define the update function to improve the Actor model’s task execution
def update_actor_model(task, feedback):
# Update the task execution based on feedback
new_task = apply_feedback_to_task(task, feedback)
return new_task
# The Reflexion loop
def reflexion_loop(task):
for iteration in range(max_iterations):
# Actor model performs the task
output = actor_model(task)
# Evaluator model critiques the output
evaluation = evaluator_model(output)
# If the evaluation is satisfactory, exit the loop
if check_satisfaction(evaluation):
break
# Self-Reflection model generates feedback
feedback = self_reflection_model(evaluation)
# Update the task based on feedback
task = update_actor_model(task, feedback)
return task, output, evaluation
# Run the Reflexion loop
final_task, final_output, final_evaluation = reflexion_loop(task_description)
# Output the results
print(“Final Task:”, final_task)
print(“Final Output:”, final_output)
print(“Final Evaluation:”, final_evaluation)
Benefits
Implementing the Reflexion framework with Large Language Models (LLMs) like ChatGPT offers several compelling benefits, especially in domains requiring complex decision-making and iterative learning processes. Here are some of the advantages:
- Enhanced Learning and Adaptability: Reflexion enables LLMs to learn from their past actions by reflecting on feedback, which leads to improved performance over time without the need for explicit retraining or fine-tuning of the model.
- Cost Efficiency: Traditional reinforcement learning often requires substantial computational resources. Reflexion minimizes these costs by using linguistic feedback instead of weight updates, making it a more scalable solution.
- Increased Robustness: By iteratively refining their outputs, LLMs can become more robust and less prone to making repetitive mistakes, enhancing the reliability of their applications.
- Error Correction and Debugging: The Reflexion framework can be particularly beneficial for tasks such as code generation, where the model can learn to identify and fix errors in code based on unit test feedback.
- Interpretability and Transparency: The feedback loop makes it easier for developers and users to understand the decision-making process of the LLM, leading to greater transparency and trust in AI systems.
- User Experience: By consistently improving its outputs, the LLM can provide a better user experience, as it adapts to users’ needs and provides increasingly relevant and accurate information or solutions.
- Collaborative Interaction: Reflexion encourages a collaborative interaction between the model and its users, where users’ feedback is incorporated into the learning loop, personalizing the model’s responses to specific user preferences and requirements.
- Transferability of Skills: The reflexive process allows LLMs to potentially transfer insights from one task to another, leading to more generalized problem-solving capabilities.
- Research and Development: Reflexion could accelerate research in AI by allowing rapid prototyping and testing of hypotheses through the LLMs’ iterative refinement process.
- Ethical Alignment: The framework can aid in the ethical alignment of LLMs by allowing them to refine their understanding of acceptable outputs based on feedback, which can be crucial for sensitive applications.
Overall, the Reflexion framework’s iterative, feedback-based approach can lead to AI that not only performs tasks but also understands and refines its approaches, thereby mirroring a more human-like process of learning and self-improvement.
Practical Considerations
To translate the Reflexion framework from theory to practice, consider the following:
- Data Security: Ensure that all data used in the loop is secure, especially if the tasks involve sensitive information.
- Error Handling: Create robust error-handling mechanisms to deal with unexpected outputs or system failures.
- Resource Management: Keep an eye on computational resources. Reflexion can be resource-intensive, especially when iterating numerous times.
Conclusion
The Reflexion framework marks a significant leap forward in AI’s capacity for autonomous learning and adaptation. Its implementation could lead to AI systems that not only perform tasks but also understand and refine their approaches just like a human would. As this technology continues to mature, it may well become a staple in the development of intelligent, responsive AI systems across various industries.
Reference
Reflexion: Language Agents with Verbal Reinforcement Learning
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games…arxiv.org
GitHub – noahshinn/reflexion: [NeurIPS 2023] Reflexion: Language Agents with Verbal Reinforcement…
NeurIPS 2023] Reflexion: Language Agents with Verbal Reinforcement Learning – noahshinn/reflexiongithub.com